
Arabic Speech Recognition Based on Encoder-Decoder Architecture of Transformer
DOI:
https://doi.org/10.51173/jt.v5i1.749Keywords:
Sequence to Sequence ASR, Arabic ASR, Transformer-Speech Recognition, Arabic Speech to TextAbstract
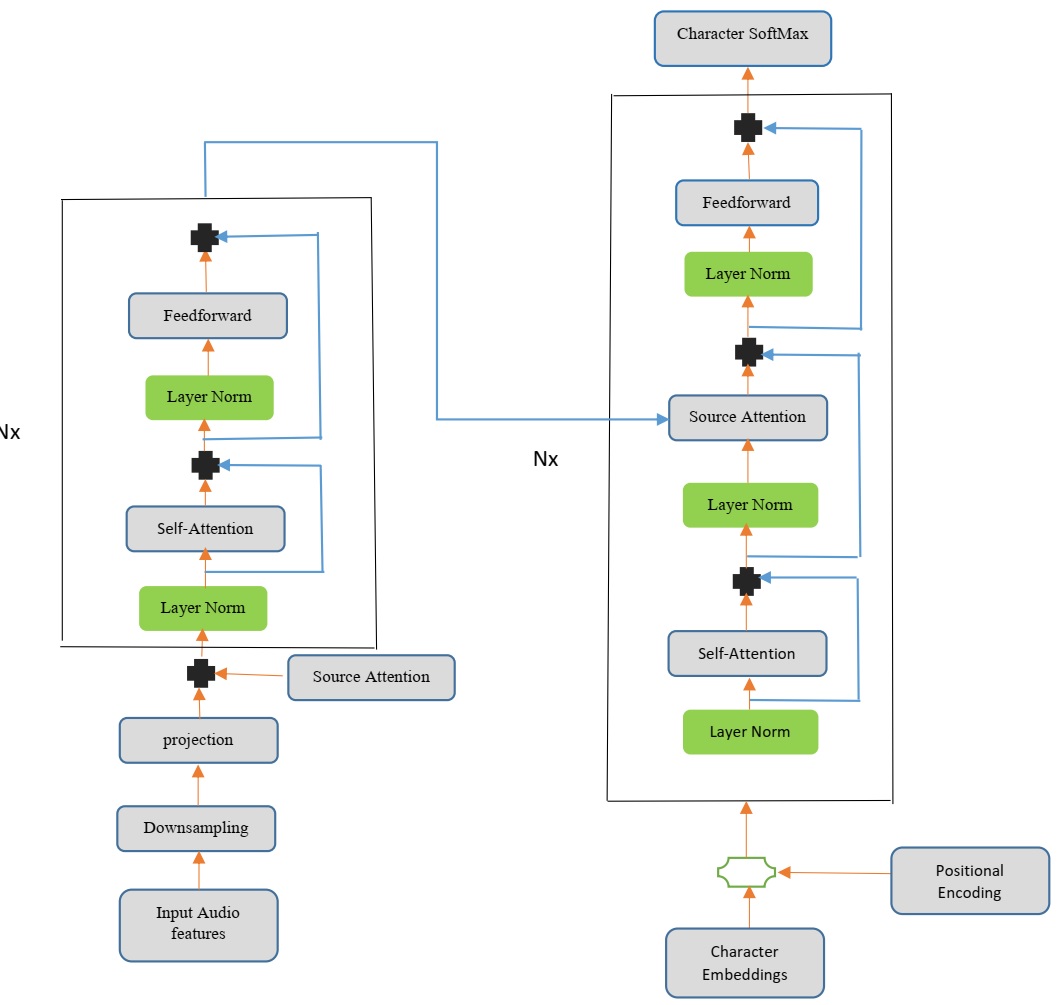
Recognizing and transcribing human speech has become an increasingly important task. Recently, researchers have been more interested in automatic speech recognition (ASR) using End to End models. Previous choices for the Arabic ASR architecture have been time-delay neural networks, recurrent neural networks (RNN), and long short-term memory (LSTM). Preview end-to-end approaches have suffered from slow training and inference speed because of the limitations of training parallelization, and they require a large amount of data to achieve acceptable results in recognizing Arabic speech. This research presents an Arabic speech recognition based on a transformer encoder-decoder architecture with self-attention to transcribe Arabic audio speech segments into text, which can be trained faster with more efficiency. The proposed model exceeds the performance of previous end-to-end approaches when utilizing the Common Voice dataset from Mozilla. In this research, we introduced a speech-transformer model that was trained over 110 epochs using only 112 hours of speech. Although Arabic is considered one of the languages that are difficult to interpret by speech recognition systems, we achieved the best word error rate (WER) of 3.2 compared to other systems whose training requires a very large amount of data. The proposed system was evaluated on the common voice 8.0 dataset without using the language model.
Downloads
References
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, et al., "Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups," IEEE Signal processing magazine, vol. 29, pp. 82-97, 2012.
F. Seide, G. Li, and D. Yu, "Conversational speech transcription using context-dependent deep neural networks," in Twelfth annual conference of the international speech communication association, 2011.
H. Sak, A. W. Senior, and F. Beaufays, "Long short-term memory recurrent neural network architectures for large scale acoustic modeling," 2014.
O. Abdel-Hamid, A.-r. Mohamed, H. Jiang, L. Deng, G. Penn, and D. Yu, "Convolutional neural networks for speech recognition," IEEE/ACM Transactions on audio, speech, and language processing, vol. 22, pp. 1533-1545, 2014.
V. Peddinti, D. Povey, and S. Khudanpur, "A time delay neural network architecture for efficient modeling of long temporal contexts," in Sixteenth annual conference of the international speech communication association, 2015.
S. Zhang, H. Jiang, S. Wei, and L. Dai, "Feedforward sequential memory neural networks without recurrent feedback," arXiv preprint arXiv:1510.02693, 2015.
S. Hochreiter and J. Schmidhuber, "Long short-term memory," Neural computation, vol. 9, pp. 1735-1780, 1997.
Y. Bengio, P. Simard, and P. Frasconi, "Learning long-term dependencies with gradient descent is difficult," IEEE transactions on neural networks, vol. 5, pp. 157-166, 1994.
R. Collobert, C. Puhrsch, and G. Synnaeve, "Wav2letter: an end-to-end convnet-based speech recognition system," arXiv preprint arXiv:1609.03193, 2016.
B. H. Ahmed and A. S. Ghabayen, "Arabic automatic speech recognition enhancement," in 2017 Palestinian International Conference on Information and Communication Technology (PICICT), 2017, pp. 98-102.
N. Zerari, S. Abdelhamid, H. Bouzgou, and C. Raymond, "Bidirectional deep architecture for Arabic speech recognition," Open Computer Science, vol. 9, pp. 92-102, 2019.
A. A. Abdelhamid, H. A. Alsayadi, I. Hegazy, and Z. T. Fayed, "End-to-end arabic speech recognition: A review," in Proceedings of the 19th Conference of Language Engineering (ESOLEC’19), Alexandria, Egypt, 2020, pp. 26-30.
A. Messaoudi, H. Haddad, C. Fourati, M. B. Hmida, A. B. E. Mabrouk, and M. Graiet, "Tunisian Dialectal End-to-end Speech Recognition based on DeepSpeech," Procedia Computer Science, vol. 189, pp. 183-190, 2021.
H. H. Nasereddin and A. A. R. Omari, "Classification techniques for automatic speech recognition (ASR) algorithms used with real time speech translation," in 2017 Computing Conference, 2017, pp. 200-207.
H. Satori, M. Harti, and N. Chenfour, "Introduction to Arabic speech recognition using CMUSphinx system," arXiv preprint arXiv:0704.2083, 2007.
S. A. Selouani and M. Boudraa, "Algerian Arabic speech database (ALGASD): corpus design and automatic speech recognition application," Arabian Journal for Science and Engineering, vol. 35, pp. 157-166, 2010.
M. Belgacem, A. Maatallaoui, and M. Zrigui, "Arabic language learning assistance based on automatic speech recognition system," in Proceedings of the International Conference on e-Learning, e-Business, Enterprise Information Systems, and e-Government (EEE), 2011, p. 1.
K. Khatatneh, "A novel Arabic Speech Recognition method using neural networks and Gaussian Filtering," International Journal of Electrical, Electronics & Computer Systems, vol. 19, 2014.
D. Yu and L. Deng, Automatic speech recognition vol. 1: Springer, 2016.
G. E. Dahl, D. Yu, L. Deng, and A. Acero, "Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition," IEEE Transactions on audio, speech, and language processing, vol. 20, pp. 30-42, 2011.
A. Graves, A.-r. Mohamed, and G. Hinton, "Speech recognition with deep recurrent neural networks," in 2013 IEEE international conference on acoustics, speech, and signal processing, 2013, pp. 6645-6649.
Y. Hifny, "Unified acoustic modeling using deep conditional random fields," Transactions on Machine Learning and Artificial Intelligence, vol. 3, p. 65, 2015.
I. Hamed, P. Denisov, C.-Y. Li, M. Elmahdy, S. Abdennadher, and N. T. Vu, "Investigations on speech recognition systems for low-resource dialectal Arabic–English code-switching speech," Computer Speech & Language, vol. 72, p. 101278, 2022/03/01/ 2022.
L. Dong, S. Xu, and B. Xu, "Speech-transformer: a no-recurrence sequence-to-sequence model for speech recognition," in 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 5884-5888.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., "Attention is all you need," Advances in neural information processing systems, vol. 30, 2017.
M.-T. Luong, H. Pham, and C. D. Manning, "Effective approaches to attention-based neural machine translation," arXiv preprint arXiv:1508.04025, 2015.
M. Sperber, J. Niehues, G. Neubig, S. Stüker, and A. Waibel, "Self-attentional acoustic models," arXiv preprint arXiv:1803.09519, 2018.
J. Gehring, M. Auli, D. Grangier, D. Yarats, and Y. N. Dauphin, "Convolutional sequence to sequence learning," in International conference on machine learning, 2017, pp. 1243-1252.
J. L. Ba, J. R. Kiros, and G. E. Hinton, "Layer normalization," arXiv preprint arXiv:1607.06450, 2016.
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "Bert: Pre-training of deep bidirectional transformers for language understanding," arXiv preprint arXiv:1810.04805, 2018.
N.-Q. Pham, J. Niehues, T.-L. Ha, E. Cho, M. Sperber, and A. Waibel, "The karlsruhe institute of technology systems for the news translation task in wmt 2017," in Proceedings of the Second Conference on Machine Translation, 2017, pp. 366-373.
A. Bapna, M. X. Chen, O. Firat, Y. Cao, and Y. Wu, "Training deeper neural machine translation models with transparent attention," arXiv preprint arXiv:1808.07561, 2018.
A. Veit, M. J. Wilber, and S. Belongie, "Residual networks behave like ensembles of relatively shallow networks," Advances in neural information processing systems, vol. 29, 2016.
G. Huang, Y. Sun, Z. Liu, D. Sedra, and K. Q. Weinberger, "Deep networks with stochastic depth," in European conference on computer vision, 2016, pp. 646-661.
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, "Dropout: a simple way to prevent neural networks from overfitting," The journal of machine learning research, vol. 15, pp. 1929-1958, 2014.
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, et al., "Common voice: A massively-multilingual speech corpus," arXiv preprint arXiv:1912.06670, 2019.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2023 Mohanad Sameer, Ahmed Talib, Alla Hussein

This work is licensed under a Creative Commons Attribution 4.0 International License.















